top of page

DATA PREPROCESSING
Limitation of data set
-
Missing data
Missing data all the most common problem face by all the data scientist. Missing data also can know as missing values. It is occurred when no data values are stored in the attributes. It is either system error or the user didn’t enter the value of the data. Some items are more likely to generate a nonresponse than others. It can cause a great impact on the conclusion that taken the data set.
-
Inconsistent data
The data in dataset is not compulsory accurate. Survey respondents were provided with the opportunity to elaborate on why they thought their data might be wrong. They might misunderstand and given wrong data for dataset. This can cause wrong prediction by using the dataset.
-
Noisy Data
Noisy data is meaningless data. The term has often been used as a synonym for corrupt data. Any data that has been received, stored, or changed in such a manner that it cannot be read or used by the program that originally created it can be described as noisy. For example, one of the review.user is written as “J��rgen + Sandra”, which is the noisy data.
-
Incomplete data
Incomplete data is “Not applicable” data value when collected. Different considerations between the time when the data was collected and when it is analyzed. It might be human, hardware, software problems
-
Useless data attribute
Some of the attribute in the dataset is unneeded in the analysis of data. These attributes can be removed from the dataset. This is because the attributes have no effect for the conclusion and the result afterwards. For example, all the country in this selected dataset is US.
Treatment
-
Data cleaning
Data cleaning is very important in data mining. Data cleaning is the process of altering data in a given storage resource to make sure that it is accurate and correct. Data cleaning including fill in missing values, identify outliers and smooth out noisy data, correct inconsistent data, resolve redundancy caused by data integration. Thus, the result of data mining will become more accurate.
-
Data reduction
A dataset may store many attributes and millions of data. Complex data mining may take a very long time to run on the complete data set. Thus, data reduction is used to obtain a reduced representation of dataset that is much smaller in volume but still produce the same or almost the same analytic results. There are many data reduction strategies, such as data cube aggregation, dimensionality reduction, data compression, numerosity reduction, discretization and concept hierarchy generation. The strategy using for this dataset is dimensionality reduction.
RapidMiner
RapidMiner is a software platform for data science teams that unites data prep, machine learning, and predictive model deployment. It is very useful as it provides many data mining techniques and help in analysis data.
After downloading the dataset from Kaggle, the dataset is exported into RapidMiner as the picture above. The dataset is found with some problems, which are missing data, inconsistent data, noisy data, incomplete data and useless data attribute.
To eliminate these problems, one of the functions of RapidMiner, which is Turbo Prep, is used. Turbo Prep is designed to make data preparation easier. It provides a user interface where your data is always visible front and center, where you can make changes step-by-step and instantly see the results, with a wide range of supporting functions to prepare your data for model-building or presentation. Turbo Prep's supporting functions are divided into five broad categories:
-
Transform - these functions help to create useful subsets of data (Filter, Range, Sample, Remove) or to modify the data in individual columns (Replace).
-
Cleanse - these functions help with missing values, duplicates, normalization and binning.
-
Generate - these functions help you generate new data columns from existing data columns.
-
Pivot - these functions simplify the task of creating summary tables (pivot tables) from your data.
-
Merge - these functions help you to combine two or more data sets (Join).
Two Turbo Prep’s function are used in dataset to clean out the data. The functions are transformed and cleanse.



The example of missing data in the dataset is shown as above. The attributes in postalCode is written as “?”.

The filter function has been used to filter out all the missing data from the dataset and left all the data that has value. The missing value is filter out instead of replacing because the postal code of a certain place is fix and cannot be replace. The filter function in RapidMiner is as above.

The attributes in review.rating is missing and written as ‘?’.

The missing value in review.rating is replacing with average value of the rating value.

The example of data inaccurate in the dataset is shown as above. The attributes in reviews.text is written as “xxxxxxxxxxxxxxxxxxx…”. These attributes have no meaning and should be eliminated.

The filter function also used in this problem to filter out the data that has contain “xxxxxxxxxxxxxxxxxxx…”. The filter function in RapidMiner is as above.
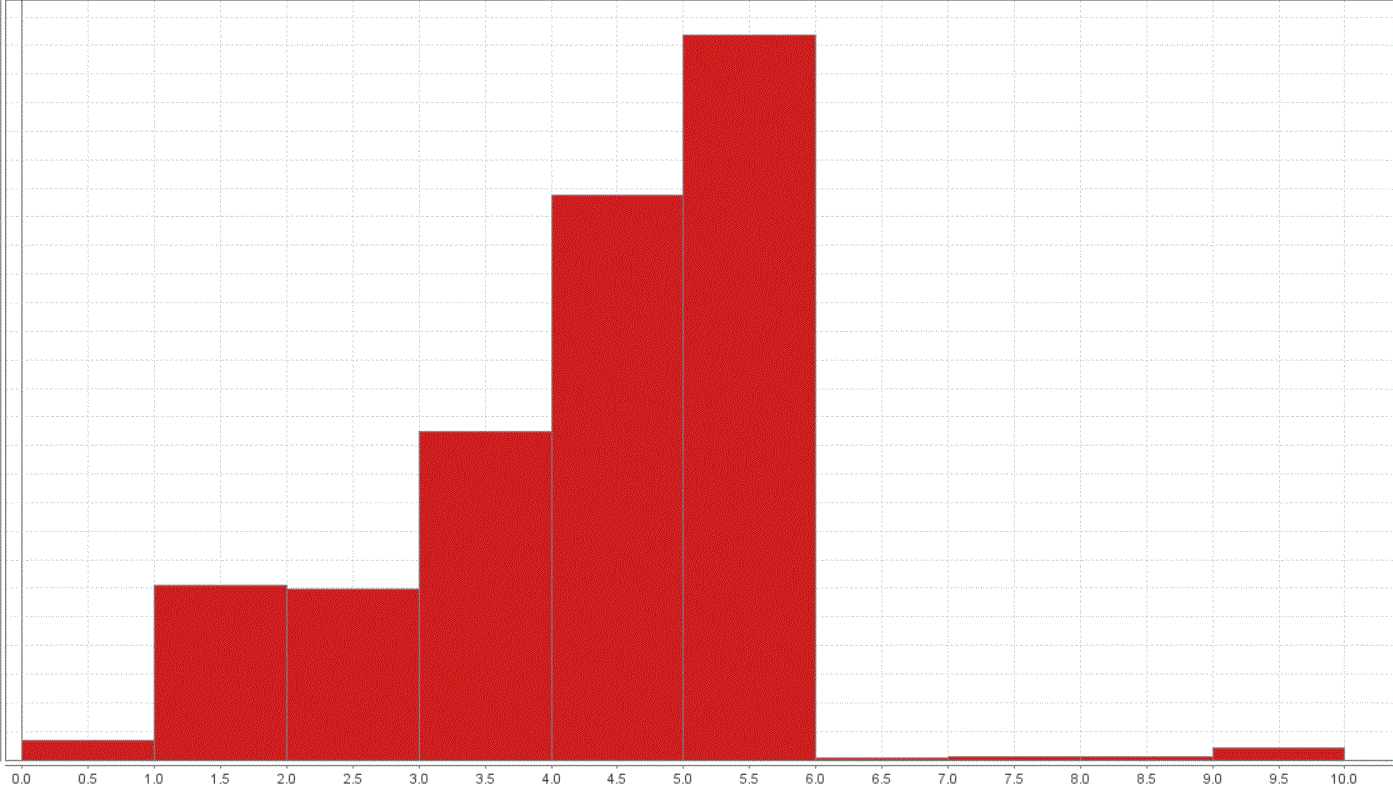
There are some attributes in the review.rating are out of bound which the maximum rating is 5 but the data given have value more than 5 as shown in the figure above.

The values of review.rating, that are out of bound, is filter out using the filter function.

The example of noisy data in the dataset is shown as above. The attributes are corrupted and cannot be understand by human. This problem can be eliminated by using the same method as above. The filter function is used to filter out the noisy data.

From the picture above, there is only one attributes for all of the data in the dataset. Thus, by using data reduction strategy the whole column can be deleted from the dataset as it will not affect conclusion and analysis of data.


There are some of the attributes has only missing values in the whole data set. This means that there are useless attributes in data set.
These attributes had to be deleted by using the strategy of data reduction, which is dimensionally reduction. These attributes will damage the data set as well as the further action in data mining.

These attributes can be transformed into year and month for easier data mining later. Thus, the attributes are first broken down into date and time. Then, the date are further broken down into year, month and date.

The data are broken down using delimiter.

These are the result after the transformation.

After data cleansing by the treatment, the data set consistent with other similar data sets in the system. This is the result after using Turbo Prop’s function to clean the data.

The statistics of the dataset after data cleansing is shown as above. All the attributes in missing column are “0”. That means that the dataset is cleaned.

The dataset is ready use for data mining task.
bottom of page